objective of machine learning System
Data + Algorithms = Results
Data + Results = Algorithms
| Objectives | Explanation |
|---|---|
| Predict a category | The model of Machine Learning helps analyze the input data and then predicts a category under which the output will fall. The prediction in such cases is usually a binary answer that’s based on “yes” or “no”. For instance, it helps with answers like, “will it rain today or not?” “is this a fruit?” “is this mail spam or not?” and so on. This is attained by referencing a group of data that will indicate whether a certain email falls under the category of spam or not based on specific keywords. This process is known as classification. |
| predict a quantity | This system is usually used to predict a value like predicting the rainfall according to different attributes of the weather like the temperature, percentage of humidity, air pressure and so on. This sort of prediction is referred to as regression. The regression algorithm has various subdivisions like linear regression, multiple regression, etc. |
| anomaly detector system | The purpose of a model in anomaly detection is to detect any outliers in the given set of data. These applications are used in banking and e-commerce systems wherein the system is built to flag any unusual transactions. All this helps detect fraudulent transactions. |
| clustering systems | These forms of systems are still in the initial stages but their applications are numerous and can drastically change the way business is conducted. In this system, the user is classified into different clusters according to various behavioral factors like their age group, the region they live in or even the kind of programs they like to view. According to this clustering, the business can now suggest different programs or shows a user might be interested in watching according to the cluster that the said user belongs to during classification. |
There are three categories of machine learning
| categories | |
|---|---|
| Supervised | In this model, the engineers feed the machine with labeled data. In other words, the engineer will determine what the output of the system or specific data sets should be. This type of algorithm is also called a predictive algorithm. For example, consider the following table: 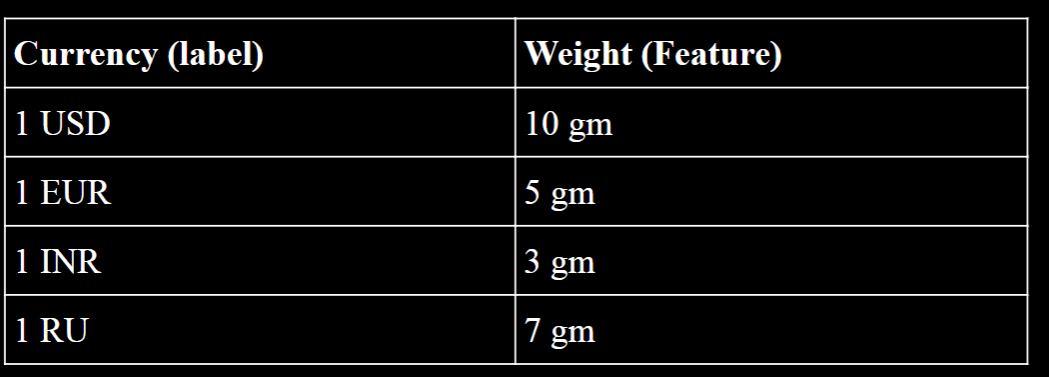 In the above table, each currency is given an attribute of weight. Here, the currency is the label, and the weight is the attribute or feature. The supervised Machine Learning system with first we fed with this training data set, and when it comes across any input of 3 grams, it will predict that the coin is a 1 INR coin. The same can be said for a 10-gram coin. Classification and regression algorithms are a type of supervised Machine Learning algorithms.Regression algorithms are used to predict match scores or house prices, while classification algorithms identify which category the data should belong to. We will discuss some of these algorithms in detail in the later parts of the book, where you will also learn how to build or implement these algorithms using Python. In the above table, each currency is given an attribute of weight. Here, the currency is the label, and the weight is the attribute or feature. The supervised Machine Learning system with first we fed with this training data set, and when it comes across any input of 3 grams, it will predict that the coin is a 1 INR coin. The same can be said for a 10-gram coin. Classification and regression algorithms are a type of supervised Machine Learning algorithms.Regression algorithms are used to predict match scores or house prices, while classification algorithms identify which category the data should belong to. We will discuss some of these algorithms in detail in the later parts of the book, where you will also learn how to build or implement these algorithms using Python. |
| unsupervised | In this type of model, the system is more sophisticated in the sense that it will learn to identify patterns in unlabeled data and produce an output. This is a kind of algorithm that is used to draw any meaningful inference from large data sets. This model is also called the descriptive model since it uses data and summarizes that data to generate a description of the data sets. This model is often used in data mining applications that involve large volumes of unstructured input data.For instance, if a system is Python input of name, runs and wickets, the system will visualize that data on a graph and identify the clusters. There will be two clusters generated - one cluster is for the batsman while the other is for the bowlers. When any new input is fed, the person will certainly fall into one of these clusters, which will help the machine predict whether the player is a batsman or a bowler. 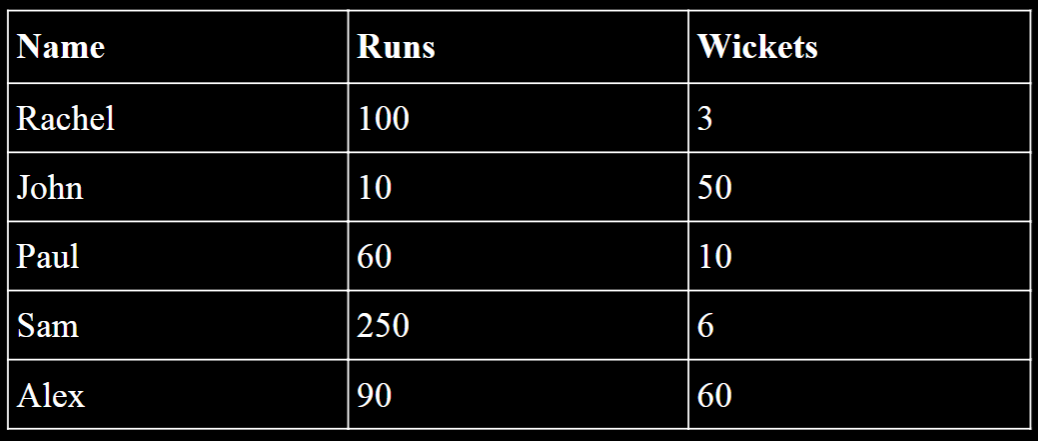 Sample data set for a match. Based on this the cluster model can group the players into batsmen or bowlers.Some common algorithms which fall under unsupervised Machine Learning include density estimation, clustering, data reduction and compressingThe clustering algorithm summarizes the data and presents it differently. This is a technique used in data mining applications. Density estimation is used when the objective is to visualize any large data set and create a meaningful summary. This will bring us the concept of data reduction and dimensionality. These concepts explain that the analysis or output should always deliver the summary of the data set without the loss of any valuable information. In simple words, these concepts say that the complexity of data can be reduced if the derived output is useful. Sample data set for a match. Based on this the cluster model can group the players into batsmen or bowlers.Some common algorithms which fall under unsupervised Machine Learning include density estimation, clustering, data reduction and compressingThe clustering algorithm summarizes the data and presents it differently. This is a technique used in data mining applications. Density estimation is used when the objective is to visualize any large data set and create a meaningful summary. This will bring us the concept of data reduction and dimensionality. These concepts explain that the analysis or output should always deliver the summary of the data set without the loss of any valuable information. In simple words, these concepts say that the complexity of data can be reduced if the derived output is useful. |
| Reinforced | This type of learning is similar to how human beings learn, in the sense that the system will learn to behave in a specific environment, and take actions based on that environment. For example, human beings do not touch fire because they know it will hurt and they have been told that will hurt. Sometimes, out of curiosity, we may put a finger into the fire, and learn that it will burn. This means that we will be careful with fire in the future. The table below will summarize and give an overview of the differences between supervised and unsupervised Machine Learning. This will also list the popular algorithms that are used in each of these models. |
Steps in building a Machine Learning System
| steps | explain | |
|---|---|---|
| 1 | Define Objective | As with any other task, the first step is to define the purpose you wish to accomplish with your system. The kind of data you use, the algorithm and other factors will primarily depend on the objective or the kind of prediction you want the system to produce. |
| 2 | Collect Data | This is perhaps the most time-consuming steps of building a system of Machine Learning. You must collect all the relevant data that you will use to train the algorithm |
| 3 | Prepare Data | This is an important step that is usually overlooked. Overlooking this step can prove to be a costly mistake. The cleaner and the more relevant the data you are using is, the more accurate the prediction or the output will be. |
| 4 | Select Algorithm | There are different algorithms that you can choose, like Structured Vector Machine (SVM), k-nearest, Naive-Bayes, Apriori, etc. The algorithm that you use will primarily depend on the objective you wish to attain with the model. |
| 5 | Train Model | Once you have all the data ready, you must feed it into the machine and the algorithm must be trained to predict. |
| 6 | Test Model | Once your model is trained, it is now ready to start reading the input to generate appropriate outputs. |
| 7 | Predict | Multiple iterations will be performed and you can also feed the feedback into the system to improve its predictions over time. |
| 8 | Deploy | Once you test the model and are satisfied with the way it is working, the said model will be sterilized and can be integrated into any application you want. This means that it is ready to be deployed. All these steps can vary according to the application and the type of algorithm (supervised or unsupervised) you are using. However, these steps are generally involved in all processes of designing a system of Machine Learning. There are various languages and tools that you can use in each of these stages. In this book, you will learn about how you can design a system of Machine Learning using Python. |
| Scenario | ||
|---|---|---|
| One | In a picture from a tagged album, Facebook recognizes the photo of the friend. Explanation: This is an instance of supervised learning. In this case, Facebook is using tagged photographs to recognize the person. The tagged photos will become the labels of the pictures. Whenever a machine is learning from any form of labeled data, it is referred to as supervised learning. | supervised |
| Two | Suggesting new songs based on someone’s past music preferences. Explanation: This is an instance of supervised learning. The model is training classified or pre-existing labels- in this case, the genre of songs. This is precisely what Netflix, Pandora, and Spotify do – they collect the songs/movies that you like, evaluate the features based on your preferences and then come up with suggestions of songs or movies based on similar features. | supervised |
| Three | Analyzing the bank data to flag any suspicious or fraudulent transactions. Explanation: This is an instance of unsupervised learning. The suspicious transaction cannot be fully defined in this case and therefore, there are no specific labels like fraud or not a fraud. The model will try to identify any outliers by checking for anomalous transactions. | unsupervised |
| Four | Combination of various models. Explanation: The surge pricing feature of Uber is a combination of different models of Machine Learning like the prediction of peak hours, the traffic in specific areas, the availability of cabs and clustering is used to determine the usage pattern of users in different areas of the city. | unsupervised |